BCH364C BCH394P 2017
BCH364C/BCH394P Systems Biology & Bioinformatics
Course unique #: 55120/55210
Lectures: Tues/Thurs 11 – 12:30 PM in GDC 4.302
Instructor: Edward Marcotte, marcotte @ icmb.utexas.edu
- Office hours: Wed 11 AM – 12 noon in MBB 3.148BA
TA: Azat Akhmetov, azat @ utexas.edu
- TA Office hours: Mon/Wed 3 PM - 4 PM in MBB 3.204 Phone: on syllabus
Lectures & Handouts
Mar 7, 2017 - Genomes II
- Homework #3 (worth 10% of your final course grade) has been assigned on Rosalind and is due by 11:59PM March 20.
- We're finishing up the slides from Mar. 2, then on to motif-finding. Note: we'll increasingly be discussing primary papers in the lectures. Here are a few (old) classics and reviews that will come up after Spring Break if you want to start looking ahead.
- Gene expression by ESTs
- Gene expression by SAGE
- Affy microarrays 1 & Affy microarrays 2
- cDNA microarrays
- RNA-Seq
- Clustering by gene expression
- Cell cycle data
Mar 2, 2017 - Genome Assembly
- Today's slides
- A gentle reminder that Problem Set 2 is due by 11:59PM March 6
- DeBruijn Primer and Supplement
- Here are a few explanations of using the BWT for indexing: 1 2
- Here are some example yeast protein sequences, annotated with their transmembrane and soluble regions (according to UniProt).
Feb 28, 2017 - Next-generation Sequencing (NGS)
- Guest speaker: Dr. Scott Hunicke-Smith, former director of the Genome Sequencing and Analysis Facility, and current VP, Molecular R&D at Sonic Reference Laboratory.
- Illumina/Solexa Sequencing (Youtube Video)
- Genome Analyzer (Youtube Video)
Feb 23, 2017 - Gene finding II
- We're finishing up the slides from Feb. 21, then moving on into Genome Assembly
Feb 21, 2017 - Gene finding
Problem Set 2, due before midnight Mar. 6, 2017:
- Problem Set 2.
- You'll need these 3 files: State sequences, Soluble sequences, Transmembrane sequences
Reading:
Feb 16, 2017 - HMMs II
- We're finishing up the slides from Feb. 18.
- News of the day: CRISPR patent! #1 #2, and #3. I recommend reading the actual decision.
Feb 14, 2017 - Hidden Markov Models
- Don't forget: Homework #2 (worth 10% of your final course grade) is due on Rosalind by 11:59PM February 20.
- Linking out to UniProt, discussed last time
- Today's slides
Reading:
- HMM primer and Bayesian statistics primer #1, Bayesian statistics primer #2, Wiki Bayes
- Care to practice your regular expressions? (In python?)
Feb 9, 2017 - Biological databases
- Just a note that we'll be seeing ever more statistics as go on. Here's a good primer from Prof. Lauren Myers to refresh/explain basic concepts.
- Today's slides
Feb 7, 2017 - BLAST
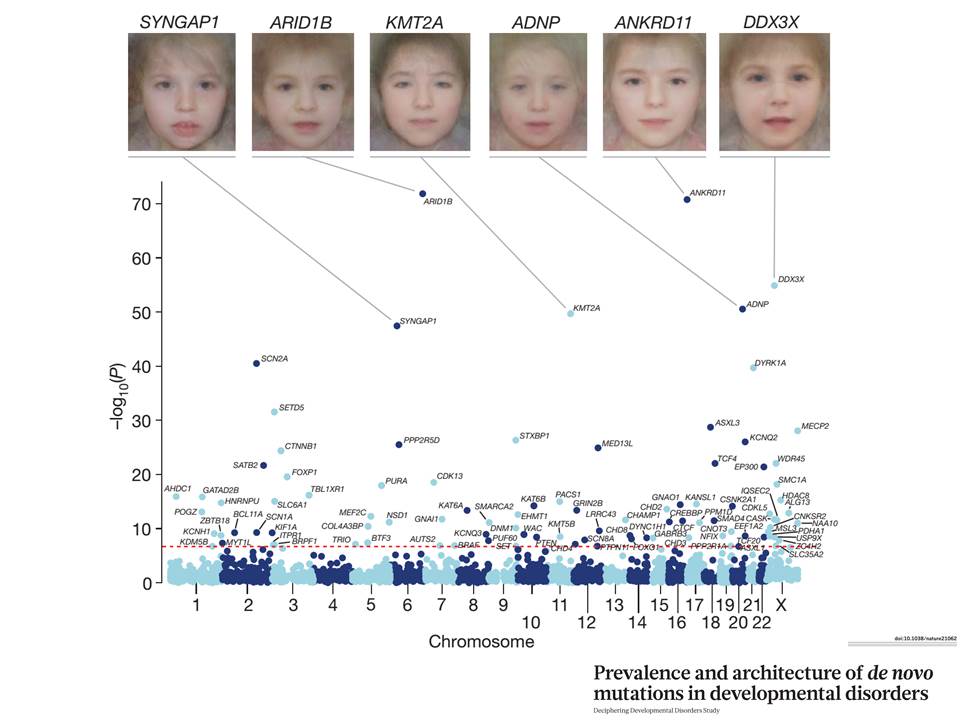
- News of the day: The UK 100K genomes project is up to 19,072 human genomes sequenced! Such data are extremely valuable for learning about human variation and gene function. For example, exome sequences of >4,000 families are revealing critical genes for developmental disorders.
- Homework #2 (worth 10% of your final course grade) has been assigned on Rosalind and is due by 11:59PM February 20.
- Our slides today are modified from a paper on Teaching BLAST by Cheryl Kerfeld & Kathleen Scott.
- The original BLAST paper
- The protein homology graph paper. Just for fun, here's a link to a stylized version we exhibited in the engaging Design and the Elastic Mind show at New York's Museum of Modern Art.
{kind=link}
Feb 2, 2017 - Guest lecture: Homologs, orthologs, and evolutionary trees
- We'll have a guest lecture by Ben Liebeskind, a postdoctoral fellow in the Center for Systems and Synthetic Biology, on decoding the evolutionary relationships among genes.
- Today's slides
Jan 31, 2017 - Sequence Alignment II
- News of the day: pig-human chimeras not science fiction?
- We're finishing up the slides from Jan. 26.
- Dynamic programming primer
- An example of dynamic programming using Excel, created by Michael Hoffman (a former U Texas undergraduate, now U Toronto professor, who took a prior incarnation of this class)
- A few examples of proteins with internally repetitive sequences: 1, 2, 3
Jan 26, 2017 - Sequence Alignment I
- news of the day--growing a mouse pancreas in a rat! This is the follow-up to one of my favorite studies from the last few years, growing a rat pancreas in a mouse!
- Today's slides
Problem Set I, due before midnight Feb. 6, 2017:
- Problem Set 1
- H. influenzae genome. Haemophilus influenza was the first free living organism to have its genome sequenced. NOTE: a few of you have pointed out that there are some additional characters in this file (from ambiguous sequence calls). For simplicity's sake, when calculating your nucleotide and dinucleotide frequencies, you can just ignore anything other than A, C, T, and G.
- T. aquaticus genome. Thermus aquaticus helped spawn the genomic revolution as the source of heat-stable Taq polymerase for PCR.
- 3 mystery genes (for Problem 5): MysteryGene1, MysteryGene2, MysteryGene3
- *** HEADS UP FOR THE PROBLEM SET *** If you try to use the Python string.count function to count dinucleotides, Python counts non-overlapping instances, not overlapping instances. So, AAAA is counted as 2, not 3, dinucleotides. You want overlapping dinucleotides instead, so will have to try something else, such as the python string[counter:counter+2] command, as explained in the Rosalind homework assignment on strings.
- For those of you who could use more tips on programming, there's a peer-led open coding hour happening on Wednesdays 4-5pm in MBB 2.232 (2nd floor lounge). It's a very informal setting where you can ask questions of more experienced programmers.
Reading:
- BLOSUM primer
- The original BLOSUM paper (hot off the presses from 1992!)
- BLOSUM miscalculations improve performance
- There is a good discussion of the alignment algorithms and different scoring schemes here
Jan 24, 2017 - Rosalind help & programming Q/A
- One of my favorite news items of the last few last years: China cloning on an 'industrial scale'. Favorite quote: "If it tastes good you should sequence it..." BGI is one of the biggest (the biggest?) genome sequencing centers in the world and employs >2,000 bioinformatics researchers.
- Statistics in Python
- We'll be finishing Python slides from last time.
Jan 19, 2017 - Intro to Python
- News of the day/Science in action: There's a huge ongoing debate raging about the development of CRISPR genome editing technology, stemming in part from an ongoing patent contest over who made key innovations in characterizing, engineering, and applying CRISPR. You can read some of the debate here, here, and here, among many other sites. There's a good chance we'll hear the major CRISPR patents decided this semester.
- REMINDER: My email inbox is always fairly backlogged (e.g., my median time between non-spam emails yesterday was 11 minutes), so please copy the TA on any emails to me to make sure they get taken care of.
- Today's slides
- Python primer
- E. coli genome
- Python 2 vs 3?. For compatibility with Rosalind and other materials, we'll use version 2.7. The current plan is for Python 2.7 support to be halted in 2020, but there is some hope (wishful thinking?) that Python 4 will be backwards compatible, unlike Python 3.
Jan 17, 2017 - Introduction
- Today's slides
- Some warm-up videos to get you started on Python: Code Academy's Python coding for beginners
- We'll be conducting homework using the online environment Rosalind. Go ahead and register on the site, and enroll specifically for BCH364C/BCH394P using this link. Homework #1 (worth 10% of your final course grade) has already been assigned on Rosalind and is due by 11:59PM January 26.
- A useful online resource if you get bogged down: Python for Biologists. (& just a heads-up that some of their instructions for running code relate to a command line environment that's a bit different from the default one you install following the Rosalind instructions. It won't affect the programs, just the way they are run or how you specific where files are located.) However, if you've never programmed before, definitely check this out!!!
- An oldie (by recent bioinformatics standards) but goodie: Computers are from Mars, Organisms are from Venus
Syllabus & course outline
An introduction to systems biology and bioinformatics, emphasizing quantitative analysis of high-throughput biological data, and covering typical data, data analysis, and computer algorithms. Topics will include introductory probability and statistics, basics of Python programming, protein and nucleic acid sequence analysis, genome sequencing and assembly, proteomics, synthetic biology, analysis of large-scale gene expression data, data clustering, biological pattern recognition, and gene and protein networks.
Open to graduate students and upper division undergrads (with permission) in natural sciences and engineering.
Prerequisites: Basic familiarity with molecular biology, statistics & computing, but realistically, it is expected that students will have extremely varied backgrounds. UGs have additional prerequisites, as listed in the catalog.
Note that this is not a course on practical sequence analysis or using web-based tools. Although we will use a number of these to help illustrate points, the focus of the course will be on learning the underlying algorithms and exploratory data analyses and their applications, esp. in high-throughput biology.
Most of the lectures will be from research articles and slides posted online, with some material from the...
Optional text (for sequence analysis): Biological sequence analysis, by R. Durbin, S. Eddy, A. Krogh, G. Mitchison (Cambridge University Press),
For biologists rusty on their stats, The Cartoon Guide to Statistics (Gonick/Smith) is very good. A reasonable online resource for beginners is Statistics Done Wrong.
Some online references:
An online bioinformatics course
Assorted bioinformatics resources on the web: Assorted links
Online probability texts: #1, #2, #3
No exams will be given. Grades will be based on online homework (counting 30% of the grade), 3 problem sets (given every 2-3 weeks and counting 15% each towards the final grade) and an independent course project (25% of final grade). The course project will consist of a research project on a bioinformatics topic chosen by the student (with approval by the instructor) containing an element of independent computational biology research (e.g. calculation, programming, database analysis, etc.). This will be turned in as a link to a web page. The final project is due by midnight, April 27, 2017. The last two classes will be spent presenting your projects to each other. (The presentation will account for 5% of the project.)
Online homework will be assigned and evaluated using the free bioinformatics web resource Rosalind.
All projects and homework will be turned in electronically and time-stamped. No makeup work will be given. Instead, all students have 5 days of free “late time” (for the entire semester, NOT per project, and counting weekends/holidays). For projects turned in late, days will be deducted from the 5 day total (or what remains of it) by the number of days late (in 1 day increments, rounding up, i.e. 10 minutes late = 1 day deducted). Once the full 5 days have been used up, assignments will be penalized 10 percent per day late (rounding up), i.e., a 50 point assignment turned in 1.5 days late would be penalized 20%, or 10 points.
Homework, problem sets, and the project total to a possible 100 points. There will be no curving of grades, nor will grades be rounded up. We’ll use the plus/minus grading system, so: A= 92 and above, A-=90 to 91.99, etc. Just for clarity's sake, here are the cutoffs for the grades: 92% = A, 90% = A- < 92%, 88% = B+ < 90%, 82% = B < 88%, 80% = B- < 82%, 78% = C+ < 80%, 72% = C < 78%, 70% = C- < 72%, 68% = D+ < 70%, 62% = D < 68%, 60% = D- < 62%, F < 60%.
Students are welcome to discuss ideas and problems with each other, but all programs, Rosalind homework, and written solutions should be performed independently. Students are expected to follow the UT honor code. Cheating, plagiarism, copying, & reuse of prior homework or programs from CourseHero, Github, or other sources are all strictly forbidden and constitute breaches of academic integrity (UT academic integrity policy) and cause for dismissal with a failing grade.
The final project web site is due by midnight April 27, 2017.
- How to make a web site for the final project
- Google Site: https://support.google.com/sites/answer/153197?hl=en
{kind=link}